知乎的HDFS多机房之路
1 背景篇
HDFS 的 Federation 架构解决了 NameNode 元信息存储的问题,使得 NameNode 具有了近乎无限横向扩展的能力。此时 HDFS 的瓶颈转变为单机房容量上限,如果能改造 HDFS 提供多机房服务,在扩容方面,HDFS 将迎来最终解决方案。
知乎于 2018 年上线 HDFS Federation 方案 nnproxy,2019 年升级 Hadoop 版本并将 Federation 方案切换至社区的 Router Base Federation。2021 年受限于单机房容量问题,迁移了一个子集群(数百台)到其他机房,迁移过程中,我们体验了一把数据拷贝、校验,任务割接,子集群停服等痛点。虽然这次迁移暂时缓解了机房容量的问题,但是随着业务的发展,HDFS 依然需要扩容,传统拷贝数据的迁移方案依然会让我们面临这些痛点。秉着一劳永逸的想法,我们决定开发自己的 HDFS 多机房方案。
2 设计篇
HDFS 多机房的问题归根结底就是专线流量的问题,因为数据的读写流量是远远大于机房之间的专线带宽的,稍有不慎就会导致专线打满,影响其他跨专线业务。
从设计上,我们需要尽最大可能避免用户读写 HDFS 跨专线,以保证专线带宽的使用在一个合理的范围内。
2.1 术语说明
地域(Region): 主要是物理上的地域比如市、县。一个 Region 会有多个机房。跨 Region 的专线成本和延时都会比较高。
机房(Zone):物理上的一个机房,一般几千到几万台机器会组成一个机房。
可用区(Avaliable Zone,简称 AZ): 指由多个 Zone 组成的可用区。AZ 和 AZ 之间通过专线连接,AZ 之间的距离一般不会太远(<100公里)。通常我们说的跨机房流量,指的就是 AZ 之间的专线流量。
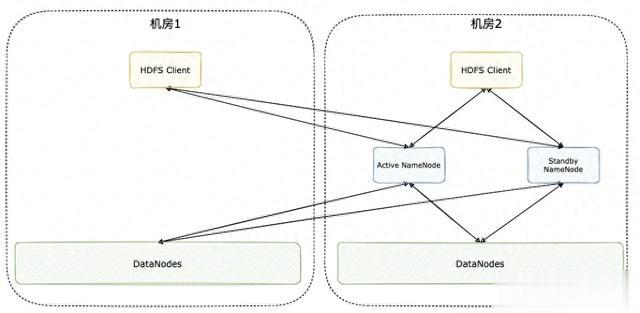
HDFS 多机房:指 HDFS 单集群(对外提供统一的入口),NameNode 部署在主要机房,DataNode 部署跨越多个机房或 AZ,不同的机房与 AZ 之间存在专线的物理限制。
多机房的架构如下:
2.2 跨机房流量分析
要想控制跨机房流量,我们必须了解流量的来源,跨机房流量主要来源于以下场景:
文件读取:比如运行在机房 1 的计算任务要读取机房 2 存储的数据,就会产生跨机房的专线流量。
文件写入:HDFS 在写入数据时会通过 pipeline 的方式写入 3 个副本,如果这三个副本所在的 DataNode 节点不在同一个机房,或者写入的客户端与这三个 DataNode 节点不在同一个机房,就会产生跨机房流量。
副本转移(Balancer 与 Mover):Balancer 是 HDFS 自带的数据迁移工具,用于平衡 DataNode 的存储水位线,会将存储负载较高的 DataNode 上的数据拷贝至存储负载较低的 DataNode,如果拷贝数据的 DataNode 不属于同一机房,就会产生跨机房流量。Mover 是 HDFS 自带的另一个数据迁移工具,用于迁移不符合异构存储策略(storage policy)的文件块,与 Balancer 类似,拷贝数据时也可能会产生跨机房流量。 副本恢复:HDFS 会存在副本坏掉,或者节点宕机的情况,此时集群会在 DataNode 间拷贝数据以恢复丢失副本,如果此时互相拷贝数据的 DataNode 不属于同一机房,就会产生跨机房流量。
Shuffle 数据传输:OLAP 计算框架如 MapReduce,Spark 等,计算节点之间会通信,传输数据,如果计算节点跨机房通信,则会产生跨机房流量。
2.3 流量缓解方案
在分析出跨专线流量的来源后,我们就可以针对这些场景做出对应优化。
2.3.1 调度任务优化
我们利用 Yarn 的 label 功能和 Yarn Federation 将资源队列进行了划分。我们将资源队列使用的计算节点与机房强绑定,在同一个资源队列里,其计算任务只能调度到同一机房的节点运行,不会存在跨机房的情况,避免了 shuffle 数据跨机房。
2.3.2 文件读取优化
HDFS 是通过副本冗余(一般为 3 副本)的方式来保证数据的可用性,任意一个副本都可以提供完整的数据读取服务,所以我们可以将副本跨机房放置,让每个文件在每个机房至少存在一副本。在客户端读取数据时,优先读取本机房的副本即可。
优先读取本机房的副本取决于 HDFS 的一个机制:客户端在发起读取请求时,NameNode 会按照副本所在 DataNode 的网络拓扑位置(如机架和机房),计算每个副本到客户端的距离,按照距离由近到远的顺序,依次返回副本列表。
如何规划节点与节点之间的网络拓扑与距离,使得同机房距离近,不同机房距离远,这里就需要对 HDFS 代码进行一些定制,具体参考细节篇。
2.3.3 文件写入优化
文件写入主要分为以下几类:
- 调度任务( ETL 任务)运行过程中产生的中间结果文件,不参与下游调度任务计算,如 /tmp/hive 里的文件;
- 调度任务产生的最终结果文件,参与下游 ETL,如 Hive 表的数据;
- 用户自己产出的数据文件,用途比较单一,如算法模型文件等。
针对场景 1,在基于调度任务不会跨机房的前提下,我们提出了 native write 的概念,native write 是指客户端在哪个机房请求写入数据,数据副本将会全部放置到请求写入的机房。比如机房 1 的客户端请求写入数据,则最后写入的数据 3 副本都在机房 1,不可能存在其他机房。
针对场景 2,我们评估了流量,虽然此类文件每天的增量十分惊人,但是在写入时刻的流量反而是比较可控的,我们直接开启双写,即在每个机房都写入至少一副本。
针对场景 3,我们内部有算法模型的代理下载服务(UnionStore)。在客户端发起读取数据的请求时,它会将算法模型从 HDFS 先缓存到本机房,然后再从本机房返回给算法在线容器,做到缓存一次,读取多次。因此算法模型的下游只有 UnionStore,读取流量完全可控。所以算法模型文件放在哪个机房并不重要,只要写入的时候不跨机房写入即可,我们对这写文件也开启了 native write。
文件写入的优化同样需要对 HDFS 代码进行一些定制,具体参考细节篇。
2.3.4 Balancer 与 Mover 优化
Balancer 和 Mover 判断两个 DataNode 之间是否可以拷贝数据的依据是 org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy#isMovable 这个方法,我们添加的 HDFS 多机房副本放置策略对这个方法进行了实现,规定了只有两个 DataNode 在同一个机房时,Balancer 和 Mover 才能在这两个 DataNode 之间拷贝数据。
另外,我们开发了全新的副本迁移工具(AzMover),AzMover 可以做到与 Balancer 和 Mover 同样的事情,并且具有更多的功能,细节参考工具篇。
2.3.5 副本恢复优化
在副本丢失,需要恢复时,我们实现的副本放置策略会优先从本机房的剩余的可用副本拷贝,在本机房没有副本的情况下才会跨机房拷贝,来尽量避免跨机房拷贝副本。
2.4 总结
HDFS 多机房方案在设计上总结起来可以描述如下:
● 多机房的 DataNode 直接跨机房组成一个集群,向相同的 NameNode 汇报;
● 副本放置策略感知 AZ,对重要数据强制多 AZ 进行分布,也就是这些数据在写入时,会保证每个机房至少存在一个副本,供其他机房的客户端读取;
● 每个 Client 在读取文件的时候,优先读取本机房的副本,避免产生大量的跨机房读流量;
● 计算任务需要避免跨机房,需要通过 Node Labels 或者 YARN Federation 的技术进行隔离。
3 细节篇
3.1 网络拓扑实现
HDFS 的网络拓扑完全基于 org.apache.hadoop.net.NetworkTopology这个类,它会将所有 DataNode 节点按照机架(rack)构建成树形结构。HDFS 的默认实现里,所有的 DataNode 都会被放置在一个默认机架里,这时因为所有节点间的距离都相同,所以不会有距离的概念。
网络拓扑可以使用命令:hdfs dfsadmin -printTopology 来查询,查询的输出大致如下:
Rack: /default-rack 1.1.1.1:9866 (data01.az1.com) 2.2.2.2:9866 (data02.az1.com) 3.3.3.3:9866 (data03.az2.com) 4.4.4.4:9866 (data03.az2.com)而网络拓扑的构建依赖于 org.apache.hadoop.net.DNSToSwitchMapping 这个类,NameNode 会在 DataNode 向自己注册时,使用这个类解析出 DataNode 所在机架。所以想自己构建网络拓扑,实现 org.apache.hadoop.net.DNSToSwitchMapping 即可。
这里最简单的实现方式就是直接采用 HDFS 自己提供的 ScriptBasedMapping,它会以 DataNode 的 ip 和地址作为参数,调用一段用户自定义的 shell 脚本来查询 DataNode 所在的机架,并且为了效率,一旦解析出某个 DataNode 的机架信息,这些信息将会被缓存下来,避免下次再调用 shell 脚本。
但是基于 ScriptBasedMapping 有一些缺点:
- 基于 shell 实现,脚本的调用速度不可控,并且 Fork 出了独立于 NameNode 的外部进程,有一定的风险;
- 这个类不仅仅会在 DataNode 注册时被调用,在客户端向 NameNode 发起请求时,也会被调用,如果客户端节点(如 k8s 的容器)不能被自定义脚本解析,它将不会缓存客户端的 rack 信息,这意味着,每次不能被解析的客户端发起请求时,都会调用这个脚本,影响性能。
基于以上缺点,我们自己实现了org.apache.hadoop.net.DNSToSwitchMapping这个类,而没有采用 HDFS 原生提供的ScriptBasedMapping。
我们的实现叫 LocalFileDNSToSwitchMapping,顾名思义,它会将网络拓扑信息存放在一个本地文件,监听本地文件并定期更新该文件到内存,每次请求过来时,直接在内存查询,这样哪怕是遇到不能解析的节点,也能很快返回结果。
文件的内容被设计如下:
{ "1.1.1.1": "/az1/rack1", "2.2.2.2": "/az1/rack2", "3.3.3.3": "/az2/rack3", "4.4.4.4": "/az2/rack4"}拿节点 1.1.1.1 举例,表示节点 1.1.1.1 在 可用区 az1 的机架 rack1 上。
此时如果再用命令查看网络拓扑,会得到如下结果:
Rack: /az1/rack1 1.1.1.1:9866 (data01.az1.com)Rack: /az1/rack2 2.2.2.2:9866 (data02.az1.com)Rack: /az2/rack3 3.3.3.3:9866 (data03.az2.com)Rack: /az2/rack4 4.4.4.4:9866 (data04.az2.com)距离的计算的权重如下:
distance(1.1.1.1, 2.2.2.2) = distance(rack1, rack2)distance(1.1.1.1, 3.3.3.3) = distance(az1, az2) + distance(rack3, rack4)AZ 之间的距离远远大于 rack 之间的距离,所以同一机房的副本会优先读取。
3.2 副本放置策略实现
NameNode 在决定往哪些 DataNode 写数据时,完全取决于 org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy 类中的 chooseTarget 方法。写入文件,增加副本,恢复副本都是以此方法为准。在决定哪些 DataNode 的副本需要被删除时,则是以方法 chooseReplicasToDelete 为准。
我们实现了一个全新的 BlockPlacementPolicy叫做 BlockPlacementPolicyAvailableZone,它能够根据配置的副本放置规则(简称 azpolicy),实现以下功能:
- 在写入副本或增加副本时,根据配置的副本放置规则选择指定机房的 DataNode 写入;
- 写入时如果存在跨专线的情况, 保证 DataNode 构建的 pipline 只会过一次专线;
- 删除副本时,根据配置的副本放置策略选择指定机房的 DataNode 上的副本删除。
首先是 azpolicy 的配置与更新方式。
一开始我们想要将 azpolicy 放置到文件元信息的 xattr 里,并且增加 azpolicy 更新的 RPC 方法,跟客户端打通,这样做的好处是能以类似 hdfs dfsadmin 的方式更新 azpolicy。但是我们发现这样会对 BlockPlacementPolicy 的 API 有较大的改动,而且 azpolicy 的改动不是一个特别频繁操作,所以我们选择了将 azpolicy 写入到本地文件,再监听这个本地文件,如果这个文件有变化,NameNode 将读取这个文件并自动更新 azpolicy。这样对 BlockPlacementPolicy 代码的侵入性就大大降低了。
azpolicy 的文件大致如下:
{ "/": { "mainAz": "/az1", "nativeWrite": false, "azPolicy": "/az1,/az1,/az2", "disableRedundantDelete": false, "disableBlockRecovery": false }, "/tmp/hive": { "mainAz": "/az1", "nativeWrite": true, "azPolicy": "/az1,/az1,/az1", "disableRedundantDelete": false, "disableBlockRecovery": false }}azpolicy 相关字段的解释参考下面的章节。
3.2.1 azPolicy 字段含义
azPolicy 字段直接决定了副本的分布,在添加或删除副本时,会严格按照该字段指定的 AZ 顺序来改变副本的分布。此字段对 EC 副本不生效。
以下是一个简单的示例:
azPolicy 字段为 /az1,/az2,/az3。
- 写入一个文件,文件最开始写入时,为 3 副本,副本分布为 /az1,/az2,/az3;
- 减少一个副本,副本分布为 /az1,/az2;
- 再减少一个副本,副本分布为 /az1;
- 再增加一个副本,副本分布为 /az1,/az2;
- 再增加一个副本,副本分布为 /az1,/az2,/az3。
可以看到,添加副本时,按照 azPolicy 字段从左向右增加,删除副本时,则从右向左删除。
3.2.2 mainAz 字段含义
主机房,副本数如果超过了 azPolicy 所配置的个数,则会将多出来的副本放到主机房内。
另外,EC 文件的副本区别于普通文件,它的每一个副本都不相同,所以不允许 EC 文件副本跨机房放置,只能放在同一个机房,这里的 mainAz 字段也代表了 EC 副本能放置的机房。
3.2.3 nativeWrite 字段含义
nativeWrite 是专门针对不参与下游计算的路径所设置的参数,开启后,客户端在哪个机房发起的写请求,就会将副本写入哪个机房。该配置优先级最高,会忽略 azPolicy 字段和 mainAz 字段。nativeWrite 主要是为了解决 /tmp/hive /var/log 这一类无需跨机房放置副本的路径。
3.2.4 disableRedundantDelete 与 disableBlockRecovery 字段含义
我们拿一个场景举例,假设一个文件,当前的副本分布是 /az1,/az1,/az1,但是它被 /az1 和 /az2 的客户端同时读取,很明显,/az2 的客户端去读这个文件的时候,就会产生跨机房流量。此时的优化策略是将这个文件的副本在两个机房放置,但是不管是以 /az1,/az1,/az2 还是 /az1,/az2,/az2 的形式放置,都会导致有一个机房存在单点故障,所以这个时候需要将文件从 3 副本升级到 4 副本,以 /az1,/az1,/az2,/az2 的方式放置。
升副本的方式可以用 hadoop fs -setrep 的方式实现,但是这种方式有以下弊端:
- 对大目录整体进行升降副本操作时速度不可控,会导致专线流量不可控,因为真正触发副本升降的时间取决于 NameNode 的内部检查线程;
- 无法对已有副本的分布进行变更,简单举个例子,副本从 3 升到 4 时,只能从 /az1,/az1,/az1 到 /az1,/az1,/az1,/az1 或 /az1,/az1,/az1,/az2,而无法直接到达 /az1,/az1,/az2,/az2 的分布。
所以我们自己开发了迁移副本的工具 AzMover(详见工具篇),AzMover 利用 DataNode 的 replceBlock 接口,能够快速改变文件的副本分布。
用 AzMover 升副本时,我们有以下两种方式:
- 先将 block 的副本从 3 拷贝到 4,再设置文件元信息里的副本数为 4,但是在拷贝副本和设置文件元信息之间存在一定的时间差,可能触发 NameNode 冗余块删除的逻辑,导致刚刚拷贝的副本被删除,此时 disableRedundantDelete 字段可以帮我们临时禁用某个路径下的冗余块删除逻辑;
- 先设置文件元信息里的副本数为 4,再将文件的副本从 3 拷贝到 4,但是在设置文件元信息和拷贝副本之间存在一定的时间差,可能触发 NameNode 丢失块恢复逻辑,影响拷贝副本,此时 disableBlockRecovery 字段可以帮我们临时禁用某个路径下的丢失块恢复逻辑。
另外,在极端情况下,比如某个机房内的 DataNode 因为各种原因宕机了多台,也就是会有一些文件在同一机房内的副本全部丢失,这个时候会触发跨机房恢复副本的逻辑,打满专线。此时我们可以用 disableBlockRecovery 来限制跨机房恢复副本,等待 DataNode 恢复或者用 AzMover 控制流量恢复副本即可。
基于 BlockPlacementPolicy 的设计,我们可以控制写入文件的副本分布,达到控制流量的目的。
4 工具篇
BlockPlacementPolicyAvailableZone 基本实现了副本跨机房放置策略,但是它也有一些不足:
- 副本放置策略只对新增数据有效,已经写入的存量数据不能改变其副本分布;
- 不能指定副本数,新写入的副本还是 HDFS 配置的默认副本数;
- 无法获取到整个集群的副本分布状况。
4.1 AzMover
AzMover 是为了解决存量数据不满足 azpolicy 的问题而开发出的工具。它的实现基于 DataNode 的 replaceBlock 接口,能够快速改变副本的分布。
其架构图如下:
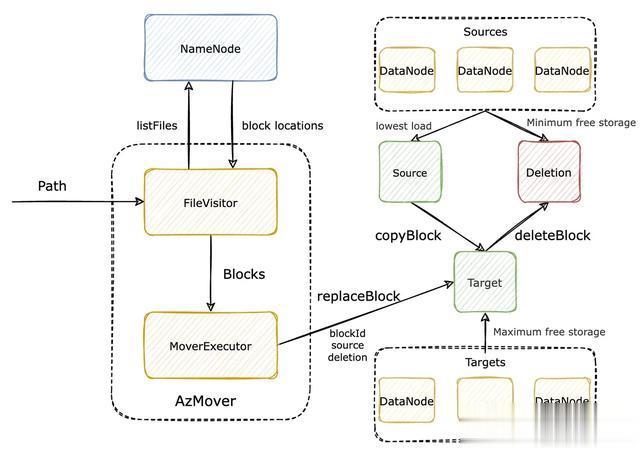
其工作流程如下:
- AzMover 接受一个或多个要迁移的路径,再通过 FileVisitor 组件向 NameNode 请求这些路径下的所有文件;
- 遍历目录拿到文件的元信息后,再从元信息里解析出文件对应的 block 列表;
- 对于每一个 block,存储其副本的 DataNode 有多个,从这多个 DataNode 中挑选当前读取负载最低的为 Source,挑选存储最紧张的为 Deletion;
- MoverExecutor 从集群中挑选一台存储比较空闲的机器作为 Target;
- MoverExecutor 调用 Target 节点的 replaceBlock 接口,让其从 Source 拷贝数据,拷贝完成后删除 Deletion 节点上的对应 block 副本。
可以看出 AzMover 其实只是个代理,真正的拷贝过程发生在 Source 节点和 Target 之间,所以上述流程 AzMover 可以支持并发,提高迁移效率。
AzMover 支持的主要功能如下:
- 副本迁移:支持按照 azPolicy 迁移或拷贝一个或多个目录下文件的副本,包括 EC 副本,并且支持修改副本数;
- 存储负载均衡:迁移过程中,作为 Target 的每台 DataNode 写入的负载基本相同,并且写入时充分考虑 DataNode 的磁盘存储情况,尽量做到存储均衡;
- 流量控制:能够稳定且精确的控制使用的跨机房带宽。
下面我们分别来介绍一下 AzMover 各个功能是如何实现的。
4.1.1 副本迁移
副本迁移主要是调用 DataNode 的 replaceBlock 接口,具体代码实现可参考 org.apache.hadoop.hdfs.server.balancer.Dispatcher 这个类。
迁移副本的时候,需要尽量避免跨机房拷贝数据,比如文件的副本需要从 /az1,/az1,/az1 迁移到 /az2,/az2,/az2,可以先从 /az1 拷贝单副本到 /az2,再从 /az2 拷贝剩余的两副本。
但是对于 EC block,其每一个副本都不相同,只能将所有副本全部拷贝,不能采取上述优化,我们举个例子:
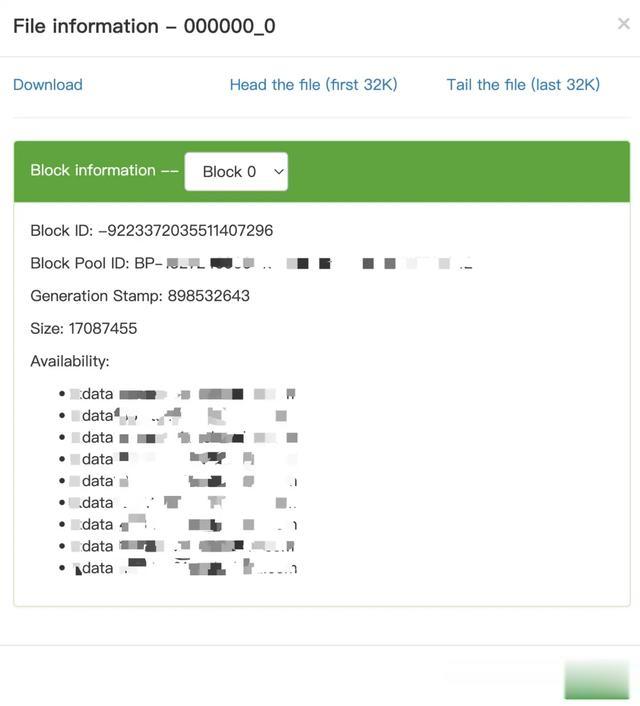
这是 HDFS web 页面的截图,这个文件是 EC 文件,编码格式为 RS-6-3-1024k,只有 1 个 block,这个 block 一共有 9 个副本,每个副本具有不同的 block id,而图中显示的 block id -9223372035511407296 仅仅只是它 9 个副本中的其中一个,其余 8 个 副本的 block id 和所在节点可以通过方法 org.apache.hadoop.hdfs.util.StripedBlockUtil#parseStripedBlockGroup 来计算。
4.1.2 存储均衡与负载均衡
在副本迁移的过程中,我们要保证以下两点:
- 负载均衡,也就是每台 DataNode 读写的请求要尽量均匀,不影响正常用户的读写;
- 存储均衡,也就是尽量将副本迁移到存储空闲的机器。
这是一个慢慢优化的过程,我们经历了一些比较有意思的实践,下面介绍一下我们方案的演进过程。
方案一:最开始我们参考了 org.apache.hadoop.hdfs.server.blockmanagement.AvailableSpaceBlockPlacementPolicy 来做存储均衡,简单来说原理如下:首先随机选取两个 DataNode 作为候选节点,再比较两个节点的剩余存储空间,选出剩余存储空间最大的节点,写入数据。这种办法在 AzMover 并发较低的情况下比较有用,但是一旦 AzMover 的并发增加,写入会都集中到存储空闲的机器上,导致存储空闲的机器负载较高。
方案二:后来我们调整了方案,挑选存储最低的一批节点进行写入,每个节点写入的并发一样,保证负载均衡,写一段时间后轮换节点,再次挑选存储最低的一批节点进行写入。
但是这样依然存在一些问题:在集群每个节点存储都比较均匀的情况下,写一段时间后,轮换节点,新挑选的一批存储最低的节点确实进行了轮换,的确能够保证整个集群的存储均衡;
但是,当集群内的节点存储不均匀的情况下,比如新加一批机器的时候,由于新机器没有任何数据,不管轮换多少次节点,存储最低的一批节点都是新加的机器。此外由于 AzMover 是按照路径进行迁移,这样会导致最近迁移的路径都集中在这些新加的节点,从而造成数据热点。比如在迁移一个 PB 级别 Hive 表对应的数据目录时,正好新加了 100 台 DataNode,这会导致这个表的数据都集中在新加的 100 台 DataNode 上,在季度末或者年底的时候,需要扫这个表较多数据时,这些 DataNode 就成为了热点机器。
方案三:这也是我们最后的解决方案,每次挑选集群存储最低的前 2/3 (这个比例可以根据集群规模自行调整)节点,再到这些节点随机选出一批进行写入,每个节点写入的并发一样。举个例子,假如集群有 3000 台 DataNode,每次选出 2000 台最空闲的节点,再到这 2000 台里面随机挑选 1000 台进行写入,每个节点写入并发为 1 。这样能既可以保证存储均衡,也能保证负载均衡。但是注意每个 DataNode 的写入并发不要太高,最好是不超过其磁盘数的一半,否则对正常的读写请求有较大影响。
4.1.3 流量控制
在使用 AzMover 迁移副本时,特别是跨专线迁移副本时,我们需要根据专线带宽控制流量。
HDFS 本身能够限制 replaceBlock 使用的带宽,它内部是以一种类似令牌桶的方式实现,在使用时,我们只需要给配置项:dfs.datanode.balance.bandwidthPerSec 一个合适的值即可,其含义是单个 DataNode 在拷贝副本时,能使用的最大带宽。
结合上一章节我们描述的方案三,我们开发出了以下两种用法:
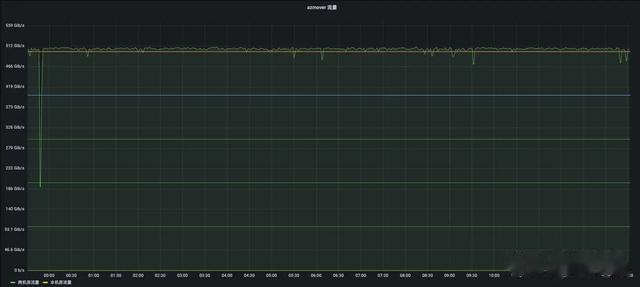
同机房拷贝副本:比如 /az1,/az1,/az2 要迁移成 /az1,/az2,/az2 的分布时,就只需要在同机房拷贝副本。同机房拷贝副本的特点是,拷贝带宽几乎无限,但是需要保证每台 DataNode 的负载不要太高。设置 dfs.datanode.balance.bandwidthPerSec 为 1GB(足够高即可),再依据方案三,每次选 1000 台进行写入,每个节点的写入并发设置为 1,整个集群拷贝流量能够保持在 100-200GB/s,一天能拷贝 10P 以上的数据。下图是我们在进行数据迁移的时候,截取的线上监控:

跨机房拷贝副本:比如 /az1,/az1,/az1 要迁移成 /az1,/az1,/az2 的分布时,就需要跨机房拷贝。跨机房拷贝副本的特点是,需要准确的控制带宽的用量,首先流量不能过大,打满专线带宽,也不能过小,影响迁移效率。这时我们设置 dfs.datanode.balance.bandwidthPerSec 为 512MB/s,再根据方案三,每次选取 128 个节点写入,每个节点写入的并发数设置为 5,因为每个节点设置 5 个写入并发,正好能打满设置的 bandwidth,这样带宽就被控制为:128*512MB/s=64GB/s=512Gb/s。下图是我们在进行数据迁移的时候,截取的线上监控,可以看到流量相对还是比较稳定。
4.2 副本分布分析工具
HDFS 部署多机房了以后,副本都分布在不同的机房,获取每个目录下文件的副本分布情况是一件比较困难的事情,为此我们开发了副本分布分析工具。
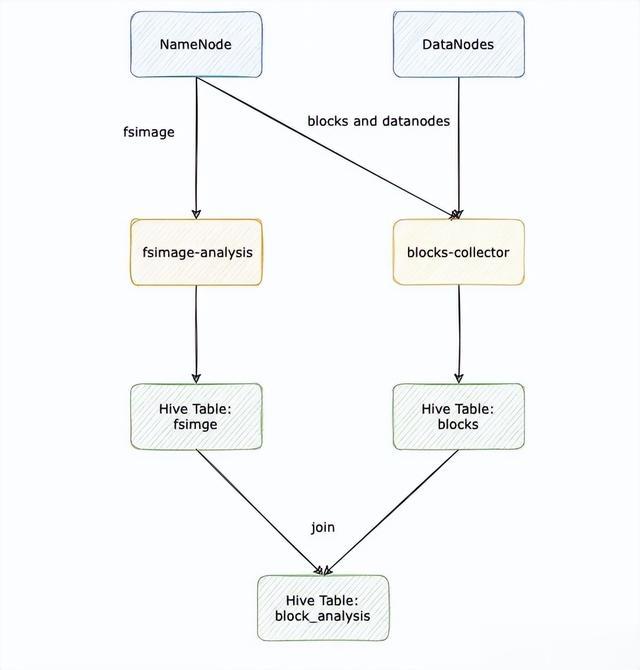
4.2.1 fsimage-analysis
对 HDFS 比较熟悉的用户而言,fsimage 是一个并不陌生的概念,它是 HDFS 的目录树快照,通过它我们可以获取整个 HDFS 集群的文件详细信息。
fsimage-analysis 是 fsimage 的解析工具,相比于 HDFS 提供的原生 fsimage 解析工具,fsimage-analysis 有以下优势:
- 更快的解析速度,我们优化了 fsimage 的解析代码,其解析速度为原来的 4 倍;
- 支持实时预览解析进度,防止 fsimage 解析卡死而不知情(这个问题在 fsimage 较大,GC 比较频繁的情况下十分常见);
- 支持直接将 fsimage 文件解析成 ORC 格式的数据,上传到 HDFS 并挂载 Hive 分区,相比于 HDFS 原生的 fsimage 解析成的 TSV 文件,具有更快的查询速度与更高的文件压缩率;
- 解析出的数据具有 block_ids 的扩展字段,可以查询每个文件对应的 block 列表;
- 解析出的数据具有 ec_id 的扩展字段,可以判断文件是否为 EC 文件,EC 的编码格式是哪种;
- 自动重试与检查点功能,解析失败从上一个检查点恢复。
fsimage-analysis 产出的 fsimage 表结构如下:
CREATE TABLE `hadoop_admin.fsimage`( `path` string COMMENT '路径', `replication` int COMMENT '副本', `modification_time` string COMMENT '修改时间', `access_time` string COMMENT '访问时间', `preferred_block_size` bigint COMMENT 'block大小', `blocks_count` int COMMENT 'block数', `file_size` bigint COMMENT '文件大小', `ns_quota` bigint COMMENT 'ns_quota', `ds_quota` bigint COMMENT 'ds_quota', `permission` string COMMENT '权限: - 开头为文件,d 开头为目录', `user_name` string COMMENT '用户', `group_name` string COMMENT '组', `ec_id` int COMMENT 'ec 策略的 id,0 为没有 ec', `block_ids` array<string> COMMENT 'block 的 id')COMMENT 'HDFS 存储快照'PARTITIONED BY ( `p_date` string COMMENT '日期分区', `name_service` string COMMENT '集群分区')ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION 'xxx';4.2.2 blocks-collector
blocks-collector 是为了获取整个集群副本的分布而开发的工具。它主要用来收集每个 DataNode 上的 block 列表。
block 的收集主要有两种方式:
- 登陆到每台 DataNode 上,遍历数据目录,找到以 blk_ 为前缀的文件名即为 block id;
- 利用 NameNode 的 API org.apache.hadoop.hdfs.server.protocol.NamenodeProtocol#getBlocks,直接获取每台 DataNode 上的所有 block。
第一种方式需要借助集群的运维工具,登陆到每个 DataNode 上进行收集,十分麻烦。因此我们选择了第二种方式,但是需要注意一点,在 DataNode block 数较多的情况下,一次拉全量可能会超过 RPC 请求的 response 的最大限制(默认 128M),可以适当调大这个参数,或者分多次拉取。
在收集到 DataNode 上的所有 block 后,我们会将 DataNode 与 block 的对应关系写入到 ORC 文件, 最后再将些文件上传到 HDFS 并挂载到 Hive 表上。
blocks-collector 产出的 blocks 表结构如下:
CREATE TABLE `hadoop_admin.blocks`( `block_id` string COMMENT 'block id', `hostname` string COMMENT 'hostname', `name_service` string COMMENT 'name service', `az` string COMMENT 'az')COMMENT 'datanode 与 block 映射表'PARTITIONED BY ( `p_date` string COMMENT '日期分区')ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION 'xxx';4.2.3 分析副本分布
利用 fsimage-analysis 与 blocks-collector 分别生成了文件与 block 的映射表和 DataNode 与 block 的映射表后,再配合简单的 ETL 即可产出整个 HDFS 文件副本分布的 Hive 表。
通过以上两张表可以产出另外一张副本分布表:
CREATE TABLE `hadoop_admin.block_analysis`( `path` string COMMENT 'path', `block_id` string COMMENT 'block id', `datanode_list` array<string> COMMENT 'datanode list', `az_list` array<string> COMMENT 'az list', `ec_id` string COMMENT 'ec id', `name_service` string COMMENT 'name service')COMMENT 'block 与 path 映射表'PARTITIONED BY ( `p_date` string COMMENT '日期分区')ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION 'xxx';ETL SQL 如下,其中 ${yesterday} 为日期占位符:
WITH fsimage_tmp AS ( SELECT *, b_id as block_id FROM hadoop_admin.fsimage LATERAL VIEW explode(block_ids) table1 as b_id WHERE p_date = '${yesterday}'), blocks_tmp AS ( SELECT * FROM hadoop_admin.blocks WHERE p_date = '${yesterday}' ), join_tmp AS ( SELECT fsimage_tmp.path AS path, fsimage_tmp.ec_id AS ec_id, fsimage_tmp.name_service AS name_service, blocks_tmp.block_id AS block_id, blocks_tmp.hostname AS hostname, blocks_tmp.az AS az, blocks_tmp.p_date AS p_date FROM fsimage_tmp JOIN blocks_tmp ON fsimage_tmp.block_id = blocks_tmp.block_id AND fsimage_tmp.name_service = blocks_tmp.name_service )INSERT OVERWRITE TABLE `hadoop_admin`.`block_analysis` PARTITION(`p_date` = '${yesterday}')SELECT max(path) AS path, block_id AS block_id, collect_list(hostname) AS datanodes, collect_list(az) AS az, max(ec_id) AS ec_id, name_service AS name_serviceFROM join_tmpGROUP BY block_id, name_service;在副本分布表产出后,通过 Spark SQL 或者 Trino 之类的计算引擎查询,基本能做到秒级返回。
整个副本分析工具的流程可以描述如下:
5 应用篇(机房迁移)
相信运维过 HDFS 的同学对机房迁移都不陌生,对 HDFS 组件来说,机房迁移意味着集群迁移,旧的 DataNode 下线,数据搬迁到新机房的 DataNode 上,也就是 TB,PB 甚至是 EB 级别的数据需要被搬迁到另外一个机房,费时费力。
最常见的解决方案是在新机房搭建一个全新的 HDFS 集群,然后通过 distcp 拷贝数据,等数据拷贝完成后,将所有 HDFS 的上层服务进行迁移。
这样做有以下缺点:
- 在数据拷贝期间,用户有可能更改已经拷贝的数据,需要校验数据,删除新集群旧数据,重新拷贝新数据,对实施迁移的工程师来说,心智负担较大;
- HDFS 上层组件,如 Yarn,Hive,Spark,Flink 等,或者是数据平台等服务,需要随着 HDFS 一起割接;
- 割接期间,由于上层服务和组件都要进行 HDFS 地址的变更,为了防止数据不一致,可能需要停服进行割接,割接完成后需要重跑当天的数据,这个过程风险系数较高,失败回滚的成本也比较巨大,有些服务可能无法回滚;
- HDFS 迁移需要动员业务同学参与,比较耗费公司的人力资源,可能导致其他项目推进受阻,影响公司业务发展。
其实知乎经历过多次机房迁移,都是采用 distcp 拷贝数据的方式,除了费时费力外,还比较还费人。而在我们多机房方案上线后不久,又迎来了一次机房迁移。在云原生的时代,机房迁移将会变得越来越常见,HDFS 不能成为短板,所以这一次我们下定决心要改变传统的迁移方式,从多机房方案入手进行 HDFS 集群迁移。
5.1 地址改造
HDFS 集群迁移无法避免的问题就是入口地址割接,但是在多机房和 HDFS Federation 的架构下,我们可以巧妙地可以规避这个问题。
首先介绍一下传统的 HDFS Federation 经典架构:
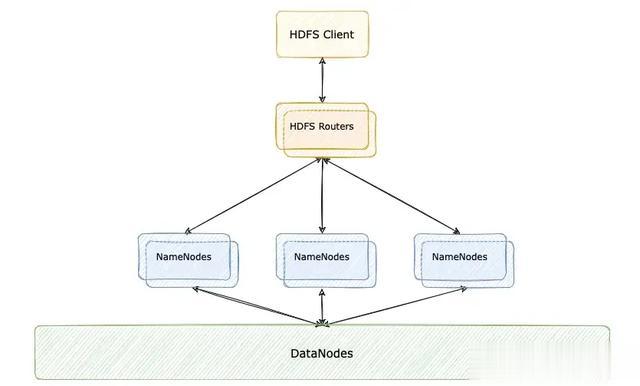
传统的 HDFS 架构下,客户端将多个 router 映射成一个 NameService,然后将配置项 fs.defaultFs 设置为 HDFS Router 映射的 NameService,达到 HDFS Router 高可用的效果。每个 HDFS Router 监听所有 NameNode,依据路径转发客户端请求。客户端的配置比较复杂,必须要以 HA 的方式配置地址,配置项比较多,当然这也不是什么大问题。
其次再来看看我们改造后的多机房架构,如下图:
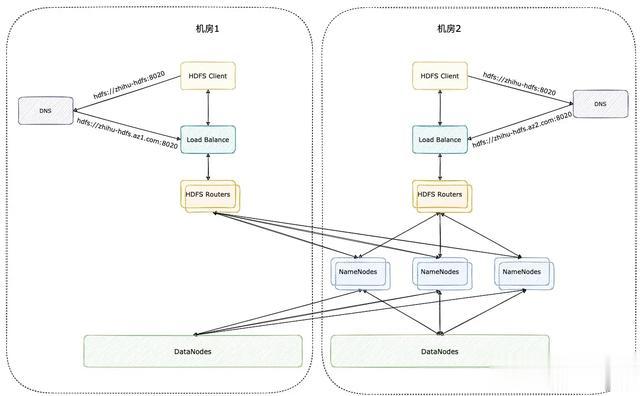
相比于原来的架构我们多机房架构做了以下改造:
- 增加负载均衡组件,这个组件会代理所有的 HDFS Router 节点,客户端访问时,会先访问负载均衡,再通过负载均衡转发。这样客户端的配置可以简化,甚至不需要 hdfs-site.xml 和 core-site.xml,只要拿到负载均衡地址便可访问,以 Flink 和 Presto 之类计算引擎为例,它们在读写 Hive 的时候只需要配置 Hive Metastore 的地址,通过 Metastore 拿到的 Hive 表 location 能直接使用,不需要额外的 HDFS 高可用配置,十分友好。负载均衡和 HDFS 客户端都有重试机制,也能够达到 Router HA 的效果,但是要注意 Router 重启后会有短暂的 Safe Mode 时间,建议重启 Router 的时候,将 Router 从负载均衡组件上摘除。此外负载均衡也具有 ip 穿透的功能,从负载均衡过来的请求将不会影响 HDFS 审计日志;
- 每个机房一套 Router 与负载均衡组件,所有 Router 共享 mount table,并且将负载均衡地址用短域名代替,去掉 FQDN。
关于短域名如何实现,我们举例说明:
比如原来我们的 HDFS 集群在机房 1,其 HDFS 负载均衡入口地址为 hdfs://zhihu-hdfs.az1.com:8020,现在我们用短域名代替入口地址后就变成了 hdfs://zhihu-hdfs:8020;另外我们将新机房(机房2)的 HDFS 入口地址配置为 hdfs://zhihu-hdfs.az2.com:8020,其短域名与原集群的入口地址相同,都是 hdfs://zhihu-hdfs:8020。此时我们将将客户端配置项 fs.defaultFs 配置成短域名 hdfs://zhihu-hdfs:8020。
这样的好处有以下几点:
- 全局地址唯一:无论哪个机房的客户端看来,HDFS 入口地址都一样,但是由于短域名会被对应机房的 DNS 服务解析成对应机房的长域名,客户端就会访问对应机房的负载均衡,从而访问对应机房的 HDFS Router,这样每个机房的 HDFS Router 仅负责转发本机房客户端的请求到 NameNode,避免 Client -> NameNode ->Router 的请求链路多次跨机房,从而导致延迟过大;
- 就近读取数据:在 Federation 架构下,NameNode 看起来,所有的客户端请求都来自 HDFS Router,而由于真实的客户端都请求本机房的 Router,这会让 NameNode 在返回 block 副本所在的 DataNode 时,将与客户端相同机房的 DataNode 排在前面,优先被读取。 这里再额外补充一点,很多公司在做 HDFS Federation 的时候,都会做 HDFS Router ip 穿透的改造,目的是确保 NameNode 的审计日志获取正确的真实的客户端 ip,我们没有做这个改造,而是通过 NameNode 机器的 iptables 禁用除 Router 以外的请求,并且在 Router 上增加了审计日志,基于这些前提,就近读取数据的功能才得以实现。
经过改造后,HDFS 具有了全局唯一的地址,在真正迁移集群的时候,只要把任务迁移到目标机房即可,不用额外改地址了。
5.2 数据迁移与任务迁移
数据迁移这一块比较简单,首先保证新增数据有单副本写入新机房,修改 azpolicy 即可。存量数据我们完全使用 AzMover,期间一共迁移了几百 P 的数据,迁移过程中用户完全无感知,而且因为是 block 级别的迁移,上层文件也不用校验一致性。
其中特别需要注意两点,第一是有些更新频率比较快的目录比如 /tmp/hive,/var/log 等,要开 native write,不用迁移,等待任务迁移完成后,这些目录下的文件就自动迁移了;第二是有些原本要删除的数据比如回收站数据,等待它自动清理即可。
迁移按照单副本到新机房,双副本到新机房,三副本到新机房的顺序即可。在一开始我们是想将两个机房的副本都设置成 2,文件总副本为 4,来避免机房内单副本的单点故障。但是在迁移过程中,我们发现单机房存在一副本和单机房存在三副本的性能其实差距不大,因为单副本不可达的情况下,也能跨机房读取数据,而单副本不可达的情况也比较少见,所以专线流量比较可控。
在所有路径单副本都迁移到新机房后的情况下,一方面继续迁移双副本到新机房,一方面就是利用 Yarn Federation 将所有任务都切换到新机房运行,因为我们的队列是与机房绑定的,所以迁移任务就只需要在我们的数据平台上更换任务的队列即可。迁移任务时,如果能够提前分析出任务的 HDFS 路径依赖,也可以按照路径提前迁移任务,不用等待所有路径单副本都迁移完成。
最后,在任务所有任务迁移完成时,就可以迁移三副本到新机房了,等待旧机房的副本都被迁移完成后,退役机器即可。
5.3 主节点迁移
利用多机房方案迁移集群一个比较关键的点在于迁移主节点,对于 HDFS 来说,需要迁移 Journode 和 NameNode,并且需要保证这两个组件在一天内迁移完成,不能让这两个组件跨机房通信,因为 NameNode 写 Journode 超时会自杀,跨专线会加剧这种情况。 Journode 和 NameNode 迁移方案已经比较成熟了,单从网上能搜到的文章就有数十篇,这里就不多赘述了。
值得一提的是,主节点完全可以做到热迁移,不停服,需要多给 NameNode 切几次主,多给集群的 DataNode 和 Router 换几次配置重启,可能花费的时间比较久。我们在迁移时,平均每天能热迁移一组 NameNode + Journalnode,期间业务方的任务比较正常,没有出现问题。
5.4 总结
得益于多机房架构,我们本次机房迁移迁数据反而变成了最简单的事情,投入的人力和时间,都比以往的迁移要少的多,最重要的是没有对业务方造成比较大的影响。
此次迁移最耗费时间和精力的事情是 Yarn Federation 的上线,以及让业务方修改 HDFS 长域名地址到短域名地址。这两件事情是属于一次投入,多次受益,如果还有下一次迁移,在 Yarn Federation 已经上线,HDFS 地址已经统一的前提下,迁移会更快。
作者:胡梦宇
出处:https://zhuanlan.zhihu.com/p/614845144

















